Why Hash?
Before breaking down what is Hash and how to implement it, let’s understand where it’s applicable and why.
Imagine you’ve arrived at a city with a mission of delivering a package to a person named Frank Zappa. You have no prior knowledge of where he lives or any information that could help you find where to delivery the package. Your only option would be knock on every door of every apartment of every building, until you find Frank Zappa. If that sounds harsh, you can picture how this task would be nearly impossible in cities with millions of people such as São Paulo, Jakarta, New York or Tokyo.
Even if you had a list with each person’s name and their adresses, you would still have to search for Frank in this list among millions of other names. A computer faces a similiar problem when retrieving info from large databases.
Hash helps getting around this. Imagine instead, with only a person’s name you could do a mathematical manipulation and arrive at this person’s address. No matter who, you would be able to use the same mathematical function. That’s the proposal of a hash, going straight to the info’s source without having to search for it.
Of course, that’s not the only porpouse. It could be used to retrieve and join information faster, to quickly match an input with a database (for example biometric entry systems), to make a search mechanism and more.

Overview
So, what is Hash?
Hash consists of reorganize the information of given data structure so that the location of the data is correlated with the data’s key (such as the name, id or value). Therefore, it’ll result in creating a function that transforms the key into a location.
Continuing our example, our transformation could be as simple as converting ‘Frank Zappa’ to decimal. As in:
F=102 R=114 A=97 N=110 N=107 ==> Frank = 10211497110107
Z=122 A=97 P=112 P=112 A=97 ==> Zappa = 1229711211297
Frank + Zappa = 10211497110107 + 1229711211297 = 11441208321404
key = 11441208321404
With the key in hands we need then to transform it to a reasonable location. For example, we could use the key to determinate Frank’s ZIP Code:
Possible Zip Codes: 99999
key = 11441208321404
Frank's Zip Code: 11441208321404 % 99999 = 34631
In our example, Frank would be realocated to 34631, Arizona. So basically, knowing only Frank Zappa by his name we would reach his address doing only a few math. In reality, 34631 would be the position in a new data structure and we would have to rearrange all information (every citizen) to a new location.
You are probably wondering: what if the information’s key points to the same location as another. In fact, that can happen and it’s called collision. There are multiple ways of handling collision. In our example, it could be as simple as having more than one person in a given address. You would still have to knock on each door, but on fewer doors. The more you avoid collisions, the fewer doors you have to knock on, but even with collisions, hashes are still faster. Also notice the size of a hash is arbitrary, it can be larger or smaller than the total number of items.
Minimal Implementation
This is a simple hash. The sole purpose of this program is learn and practice the basics of Hash Function and Hash Tables. We used C++ only as a learning languague, we did not aim to any particular implementation. I recommend checking the full code. It will basically consist in 3 parts, assign a key and a position to every element, inserting this element in a new array/list/vector and handling collisions when it happens.
Hash Function
We used a hash function to determine the position of a given object in the new array. This hash function is not optimal and it’s supposed to be only an example. This function will return the position for a given id:
int hashfunction(string id)
{
// create "unique" key and position for each element
int sum = 0;
int distribution[12] = {1, 10, 100, 1000, 10000, 10000, 10000, 10000, 1000, 100, 10, 1};
for (int i = 0; i < id.size(); i++)
sum += int(id[i])*distribution[i];
return sum%(SIZE); //where SIZE is the size of your hash
}
Then we inserted into a list, which we’ll see later why it was chosen as our storage. First we need to create it and then store each element in their position given by our Hash Function:
list<Element> *main_list;
main_list = new list<Element>[SIZE]; //create list of class Elements
void insertElement(Element &e)
{
int position = hashfunction(e.id); // calculate position
main_list[position].push_back(e); // store element in position
}
Handling Collisions
Before diving in how to handle collision, it is important to punctuate the difference between a vector and a list in C++, because it’ll help understand why we’ve chosen the latter.
A vector is a container which store elements in contiguous memory, that means vector[54] is right next to vector[53] in the memory. If you used a function like vector[53].push_back(value), it’ll fill the next position, vector[54].
A list however is non contiguous, which means list[54] does NOT comes next to list[53] in the memory. If you used a function like list[53].push_back(value) it’ll not fill list[54], but rather an empty location next do list[53] which carries the same name.
As we are using lists and list::push_back, collisions will be automaticly handled. Each position can hold multiple variables and are determined by their id. However, for the sake of completion it’s important to point out how to retrieve those informations stored in the same position in a list:
void search_id(string id)
{
/* Search for the element using Hash*/
int position = hashfunction(id);
for (Element e : main_list[position])
if (e.id == id)
{
cout << "Element info: " << e << endl;
break;
}
return;
}
Conclusion
Using an example database a simple search of three random elements was made using a standard array and a hash:
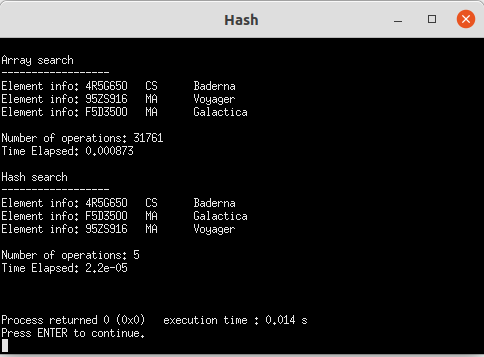
Hashes are substantially faster than normal search.
There are multiples ways and different mathematical expressions that can be used as a hash function, each of them serves a distinct purpouse. We only covered the simplest and minimal implementation.
Next we’ll check how to implement a hash to perform a hash join in SQL.